Insights
Everybody thinks they are behind
Almost every large company believes it sits in the bottom quartile of AI adoption for its industry. The arithmetic cannot work. But the feeling is...
Combine the benefits of microservices and a monolith to create a microplatform.
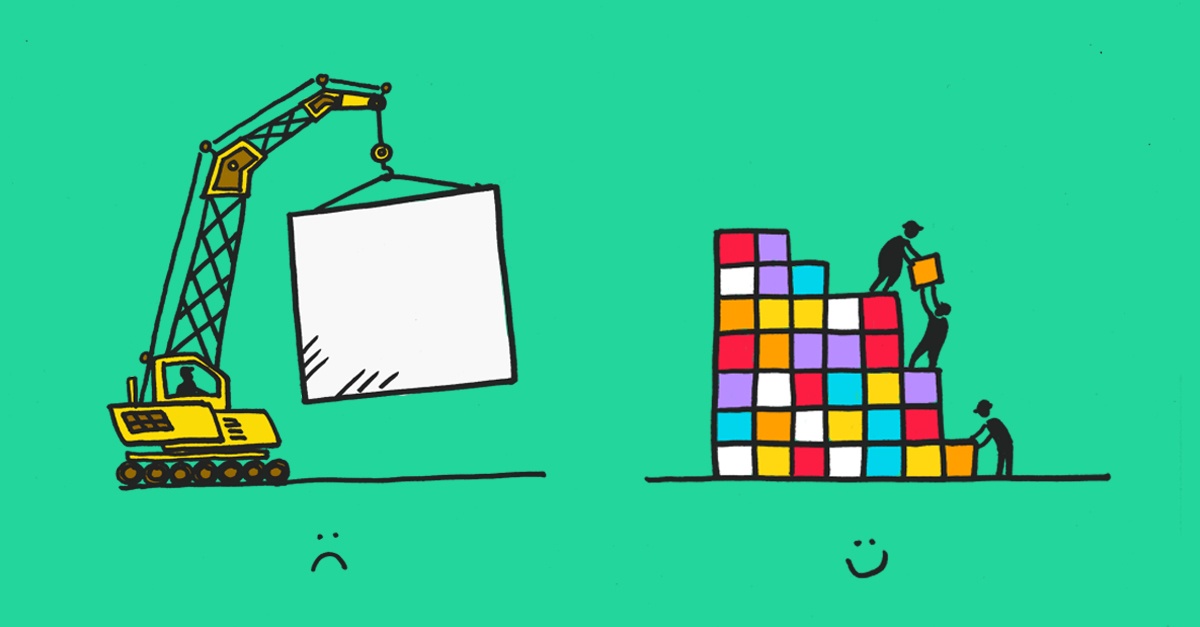
It’s really sweet when several ideas, executed together, combine to be greater than the sum of their parts.
You will know that the microservices pattern is very popular right now. For good reason, because it enables Evolutionary Architecture. Each service’s bounded context allows it to evolve on its own roadmap. This gives us a great domain-based separation of concerns so we can move very quickly while being more scalable and highly available. When done properly.
Doing this properly; therein lies the challenge! Wiring together a bunch of microservices, while maintaining version compatibility, in a way that tolerates failure, and scales the right services at the right time, can be very tricky. You could argue that it was easier when we were building monoliths. At least the whole thing was deployed in one go, and it either worked or it didn’t! But crucially, it was tested as one piece.
What we really want are the most beneficial features of both microservices and monoliths. At the same time. Hold this thought.
Typically, each microservice lives in its own separate source code repository. After all, it’s owned by a single team, so that would make sense.
Unfortunately, it doesn’t exist in isolation of the other microservices in the application. They have to talk to each other, and as each one is evolving independently, we have to be very careful to keep backwards compatibility between them.
Sometimes, however, we want to make breaking changes and we normally deal with this by using Semver to declare whether we’ve made a non-breaking change or a breaking one.
The problem with this is that it relies on a human to determine whether (potentially unknown) consumers will break because of a specific change. Sometimes this is obvious and sometimes it isn’t. Bumping the versions all over the system is also a lot of error-prone, tedious work.
Rich Hickey, one of the greatest thinkers in our industry, in probably his best talk to date, Speculation, rants against Semver, and instead advocates that we should only ever make non-breaking changes (i.e. provide more and require less). Otherwise, it’s a new thing and should be called (and deployed as) something else.
However we manage it, when we make breaking changes we usually end up running several instances (with different names, or at different versions) of our microservice, until older consumers have had a chance to catch up. It can, and invariably does, get messy quite quickly.
In a monorepo, the source code for all the microservices lives together in a single repository. This helps because developers can now make atomic commits across the whole application. So you could even change both the producer side and the consumer side of an API call, for instance, at the same time. And it could even be a breaking change, if necessary (providing you blue/green deploy both services at the same time).
This means that Semver is no longer needed for our microservices. There is only ever one version of everything and that is the commit “SHA”. The commit history becomes the history, and you know that everything at a specified commit is designed (and tested) to work together.
This sounds like we’re starting to get some of the benefits of a monolith!
Earlier this year, British Airways had a global IT failure that grounded all their planes, affecting 75,000 passengers in 170 airports around the world.
Apart from feeling the pain of everyone involved, I was also fascinated by this incident. How can a single failure have such a huge “blast radius”? Everything failed, from the website to the check-in systems to the passenger manifests to the baggage handling systems.
Details emerged that a power supply failure triggered the event (don’t ask about the UPS or backup systems), so you would imagine that it was initially fairly localised, and then the ripples turned into a tsunami, and before you know it the whole company was completely paralyzed. Check out this short video to see how a small effect can have massive consequences:
It should never be possible for any failure to affect more than its own “system”. Additionally, failures should be expected, which is a core tenet when building high reliability systems (e.g. with Erlang). We should focus on reducing the mean-time-to-repair.
As we move from monoliths to microservices, it’s easy to understand how the blast radius can be reduced dramatically. And how much more quickly we can recover when the jurisdiction is small. But what happens when the platform itself fails? The platform is a globally shared dependency that introduces hidden vulnerabilities.
So I think there’s more we can do. What if an application, and all its microservices, could be deployed to its own small platform? Instead of a large shared platform, where a failure can be catastrophic, how about many smaller platforms? Distributed across multiple datacentres and even multiple cloud providers. Let’s start thinking about “microplatforms”.
A microplatform is a fully featured platform that can be easily provisioned and completely managed by a small (two pizza) cross-functional delivery team.
By fully featured, we mean that it’s is self-healing, highly available, fault tolerant and auto-scaling, with load balancing, internal networking, service discovery and secrets management. It is small and runs on a laptop, in any cloud provider, or on-premise.
It’s cheap and disposable, as in quick and easy to create and destroy. It’s provisioned automatically, using immutable infrastructure as code principles. So we can have any number of ephemeral, production-identical platforms that we can use for testing (including performance and penetration testing), safe in the knowledge that our results are representational of a production environment.
Because they are cheap to spin up anywhere, it’s easy to make them resilient through redundancy. Because they are cloud agnostic, they can span multiple cloud providers, reducing exposure and building in the tolerance of failure. Because they are immutable and can only be changed by changing the source code, no humans are allowed into the servers. And servers without users are inherently much more secure.
I can’t overstate the importance of evolving a codebase to stamp out identical copies of these microplatforms.
Every time a human makes a manual change to running infrastructure the knowledge encapsulated in that change is lost. It’s in their head (at the time) and that’s it. It’s not captured and it can’t contribute to the evolution of the design.
When you fully embrace the principles of immutable infrastructure as code and fully automate everything, then each change is recorded in the codebase and can be verified and built upon by others to continuously evolve a good design. Just like with application code. Or with pipelines as code. Ultimately all the things should be “as code”.
Building distributed systems that assemble many microservices is hard. Developers need to orchestrate a complete application by coordinating multiple smaller services. Techniques such as service discovery help this massively. Microplatforms help even more.
Developers can design, build and test their complete systems on a laptop, which hosts a production-like platform. What gets shipped is code describing a configuration that has been thoroughly tested on an identical platform. Because all the platforms are identical.
The biggest contribution that microplatforms make is to increase the autonomy of the team. Teams design, build, run, fix and evolve their product.
To do this, they need engineers to be T-shaped and DevOps capable. Microplatforms bring the hosting of their product into the team. Because they are simple to setup and manage, the team doesn’t need to rely on another team to host their application.
This means they can move faster, and even though there is a small overhead of running the microplatform, it’s significantly less than the overhead of taking a dependency on a horizontal, shared platform and the team that manages it. This sharing creates a huge backlog of features, only a fraction of which a single team actually cares about.
The team now has significantly more available time to concentrate on delivering features that add real business value.
What does “simple to setup and manage” mean?
Well, the platform manages container instances. It schedules them across the underlying machines, scales them automatically as load increases, and restarts them when they fail.
“Cattle” instances (that don’t have state) are easier to manage than pet instances (that do). So a microplatform only has cattle. No pets allowed. Or if pets are needed then they are converted to cattle by having them access state somewhere else (like a separate data store that is managed and scaled independently; i.e. datastore-as-a-service).
It must be simple. Not just easy (hard becomes easy through familiarity, but complex rarely becomes simple - see this other great talk by Rich Hickey).
The simplest platform tech out there at the moment is Docker in Swarm Mode, with Google Kubernetes (that carries more cognitive load) following closely behind.
Docker have done a great job of distilling all the important features of a platform into something that is simple to use and easy by default. In fact, Docker in Swarm Mode is so simple that all you need are VMs running the Docker engine. Nothing else. You get all the features listed above, out of the box. For free.
You can create a cluster with “docker swarm init”, and join another VM into the cluster with “docker swarm join”. It really couldn’t be any easier. And it’s this ease, that makes it a prime candidate for microplatforms, and in my opinion it’s the first time we’ve been able to say that it’s easy enough to be managed within a cross-functional team.
Great! So we know a bit about all the 4 “M”s in the title of this post. What we haven’t done yet is talk about why bringing these concepts together makes so much sense.
One of the things that jumps right to the top, in my opinion, is Docker Stack. It’s part of the Docker client and it allows you to deploy an orchestration of services to a Swarm in one go.
It uses Docker Compose files, and it effectively does for Docker in Swarm Mode what Docker Compose does for Docker. Version 3 of the Docker Compose file specification allows you to include extra information about how a service should be deployed to a cluster, so that it can be used by Docker Stack.
Stuff like how many replicas should there be, where should they be placed, how to do updates, and how to deal with failure.
This sounds great, but it’s even better, because when you deploy a whole stack (orchestration), only the services that have changed will be updated (using zero downtime, rolling deployments). The others will be left alone.
Now, if we’re using a monorepo, then we know that versioning between services has gone away and has been replaced by a single version identifier (the Git SHA) across all the services.
So when we build our Docker images, we’ll push them to a Docker Registry tagged with this SHA. Note that if a particular service has not changed, then the layers used to make the image will all be in a local cache, and the build will be skipped.
The push will also be skipped for all image layers that have not changed, and are therefore already in the registry. And finally the deploy will be skipped for any services that have not been updated. What this leaves us with is an idempotent build phase, an idempotent push phase and an idempotent deploy phase - for the whole stack.
Which means we can build, push and deploy the whole application at once (as though it were a monolith) and only the bits (image layers) that have changed will be built, pushed and deployed. It’s like React, but for microservice deployments.
And we can redeploy any previous SHA from the registry, as a whole orchestration, and only the services that need reverting will be reverted.
Overall this is fast, efficient, and very convenient. It means we can move forward really quickly, using Continuous Deployment, and if we absolutely need to, we can go back to a last known good state in super quick time, reducing our mean-time-to-repair (although, because fixing forward is now fast it’s usually a better option).
Additionally, when we make the services “12-factor” and also use the cluster’s built in DNS based service discovery, it makes the application even more like a monolith as each service only knows itself in the context of the application, i.e. there is only one configuration, which is used by all environments. This is especially true if you link to remote APIs via ambassadors (network level proxies) that present a well-known (named) swarm-local proxy for remote endpoints.
By deploying whole orchestrations of microservices as though they were one monolithic application to production-identical platforms that we control, we have suddenly empowered our team to continuously deploy value to our customers, and reach the kaizen of continuous improvement.
At a pace, we won’t have seen before. All by just gradually evolving and improving code, just like the team already does for their application.
If you want to play with these ideas, check out this Github repository https://github.com/redbadger/stack. It contains automation and tooling for building and managing Docker in Swarm mode clusters on Mac OS X, in Google Cloud and in AWS. If you feel like it please get involved, raise issues and pull requests, or just use it to get going.
You can also here me discuss this idea in more detail in my talk on "Meet Microplatforms."
Add a Comment: